RAG - Retrieval Augmented Generation for Knowledge Intensive Task
RAG Paper를 review하고 현대 RAG 기술의 종류를 정리합니다.
이 포스팅은 25년도 광주과학기술원(GIST) 석사과정을 진행하는 제 연구 주제와 관련된 논문 리뷰 및 정리글입니다.
LLM의 Hallucination
Generative Language Model의 훈련 task는 ‘지금까지 입력받은 텍스트 다음에 올 가장 그럴 듯한 말을 만들기’이다. 여기서 ‘그럴 듯한 말’의 기준은 훈련 데이터에 의해 결정되며, 단어 자체의 생성을 학습하는 언어 모델의 경우 이 문제는 그 원리에 깊이 뿌리박혀 있는, 근본적으로 해결 불가능한 문제라고 할 수 있다.
하지만 ‘지금까지 입력받은 텍스트’의 내용을 보강하는 것으로 그 Hallucination의 정도를 줄일 수는 있다. 때문에 AI에게 잘 질문하는 능력, 즉 context를 잘 전달하는 능력은 현대인의 필수 역량으로 여겨지기 시작했다. 프롬프트 엔지니어링이라는 말까지 등장하지 않았는가.
하지만 사람이 질문의 내용을 직접 보강하는 것은 아래와 같은 한계가 있다.
1) 번거로움. 2) 사용자가 context를 모르는 경우가 존재. 3) context가 너무 많아 물리적으로 사람이 입력 불가능
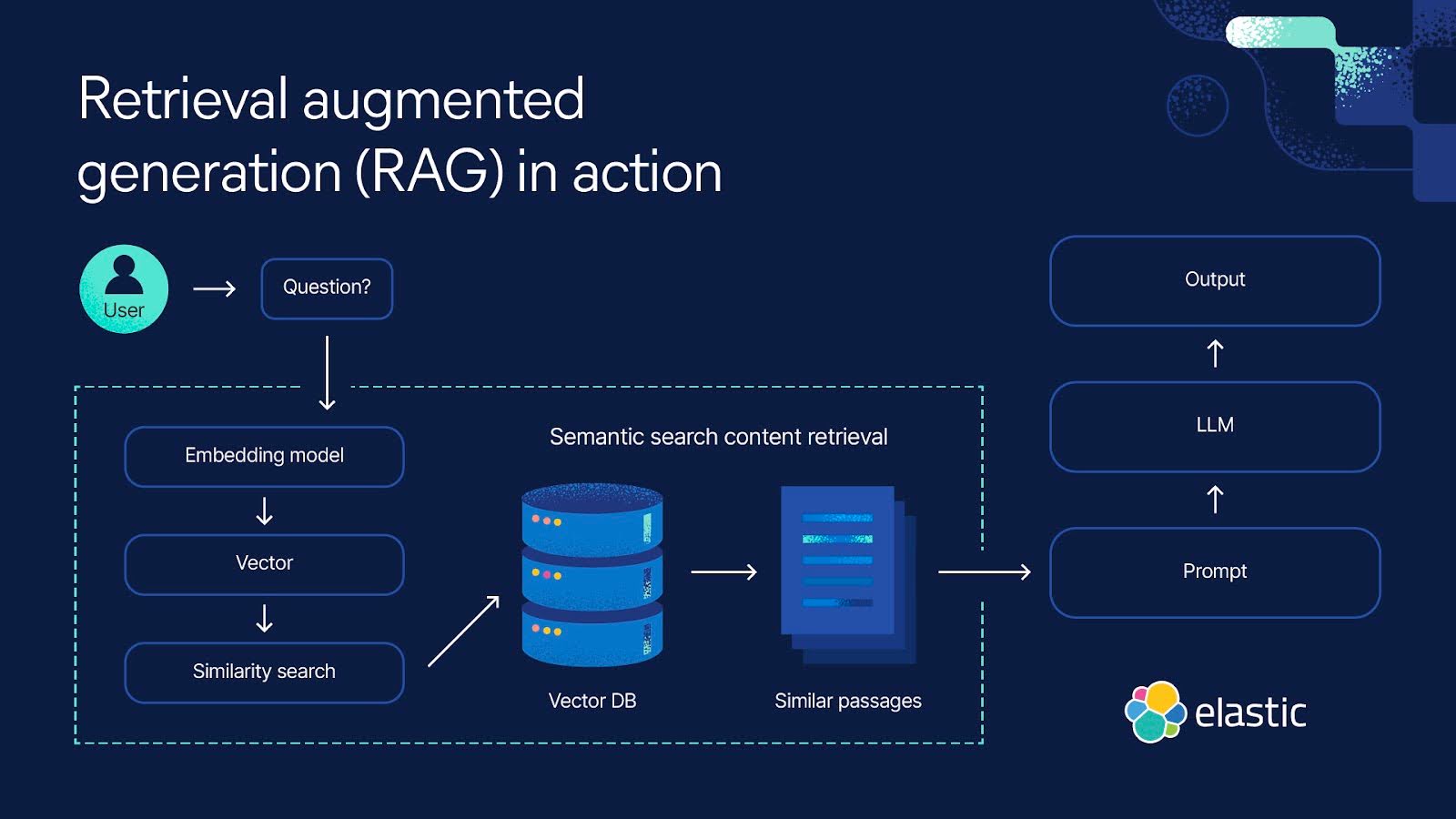
이때 이 context를 대신 전달해주는 외부 데이터베이스가 있으면 해결이 가능하다. 입력을 기반으로, 적절한 context를 외부 데이터베이스에서 끌고 와, 입력을 보강하여, 생성까지 완료하는 전체 프레임워크를 만들어 입력 데이터 증강을 자동화하는 것이다.
이같은 프레임워크를 검색-증강 생성 프레임워크(Retreival-Augmented Generation), RAG라고 부른다.
Knowledge Intensive Task
Knowledge Intensive Task란, 정확한 답변을 생성하기 위해 광범위한 외부 지식을 필요로 하는 자연어 처리 태스크를 말한다. 단순한 패턴 인식이나 언어적 추론만으로는 풀 수 없으며, Open-Domain QA, Fact Verification, Slot Filling 등이 대표적이다.
이런 태스크에서 LLM의 파라미터 안에 모든 지식을 저장하는 것은 한계가 있다. 학습 이후에 등장한 최신 정보를 반영하지 못하고, 파라미터 수를 무한정 늘릴 수도 없다. 따라서 외부 지식베이스에서 관련 문서를 검색하여 입력으로 제공하는 접근법이 자연스럽게 등장하게 되었다.
Knowledgebase Reader vs Parameterized Generator: Knowledgebase Generator로의 접근
Transformer와 LLM이 등장하기 이전 QA Task는 주로 Knowledgebase Reader 형태의 접근법이 주로 사용되었다. Knowledgebase Reader는 질의에 맞는 문서를 검색한 뒤, 해당 문서에서 정답이 될 텍스트 span을 추출하는 방식이다. 정확한 문서에 정답이 있으면 잘 작동하지만, 다양한 문서의 정보를 통합하거나 자연스러운 문장으로 생성하는 능력이 부족하다는 단점이 있다.
반면 Parameterized Generator(LLM)는 학습된 파라미터 안에 지식을 내재화하여 텍스트를 생성한다. 유연한 표현이 가능하지만, 앞서 언급한 Hallucination 문제와 최신 정보 반영의 한계가 있다.
RAG는 이 두 접근법의 장점을 결합한다. 외부 지식베이스에서 관련 문서를 검색(Retrieve)하고, 검색된 문서를 컨텍스트로 제공하여 LLM이 이를 바탕으로 답변을 생성(Generate)하도록 한다. 즉, 검색의 정확성과 생성의 유연성을 동시에 확보하는 Knowledgebase-augmented Generator로의 접근이라고 볼 수 있다.