Ontology Constrained Generation of Domain-specific Clinical Summaries
Ontology를 Input Augmentation이 아닌 Generation Constraint로 활용한 case의 논문입니다.

이 포스팅은 25년도 광주과학기술원(GIST) 석사과정을 진행하는 제 연구 주제와 관련된 논문 리뷰 및 정리글입니다.
0. 논문 정보
- 제목: Ontology-Constrained Generation of Domain-Specific Clinical Summaries
- 저자: Gaya Mehenni, Amal Zouaq (Polytechnique Montréal, LAMA-WeST)
- 학회 및 컨퍼런스: Knowledge Engineering and Knowledge Management (EKAW) 2024
- arXiv: arXiv:2411.15666v1 [cs.CL] (2024년 11월)
- 수행기관: 캐나다 몬트리올 폴리테크닉 대학교
1. Introduction & Background
Summarization
Summarization은 긴 입력 텍스트로부터 핵심 정보를 압축하여 더 짧은 텍스트를 생성하는 태스크이다. 크게 두 가지 방식으로 나뉜다.
- Extractive Summarization: 원문에서 중요한 문장/구간을 그대로 추출하는 방식. 빠르고 사실에 충실하지만, 문맥을 고려한 통합적 표현이 어렵다.
- Abstractive Summarization: 신경망 기반으로 원문을 이해하고 재구성하여 새로운 문장을 생성하는 방식. 자연스럽고 문맥 통합이 가능하지만, Hallucination에 취약하다.
최근 연구들은 두 방식의 장점을 결합한 Hybrid Approach를 사용하며, 본 논문도 이 방식을 따른다.
의료 도메인에서의 Summarization
의료 현장에서 의사들은 매일 방대한 양의 EHR(Electronic Health Records, 전자 의무 기록)을 처리해야 한다. 이는 의사들의 번아웃(clinician burnout)의 주요 원인 중 하나로 지목된다. LLM 기반 EHR 요약 자동화는 이 문제를 해결할 수 있는 유망한 접근이지만, 다음과 같은 도전과제가 있다.
- 비구조적 형식: 임상 노트는 형식이 통일되어 있지 않고 도메인 전문 용어가 집중되어 있다.
- Hallucination: LLM이 사실과 다른 정보를 생성할 경우 의료 현장에서 치명적인 결과로 이어질 수 있다.
- 도메인 특화 정보: 같은 환자 정보라도 심장내과 의사와 영상의학과 의사가 필요로 하는 요약의 내용은 전혀 다르다.
이 논문은 의료 온톨로지(Medical Ontology) 를 활용하여 위 세 가지 문제를 동시에 해결하는 프레임워크를 제안한다.
2. Methodology
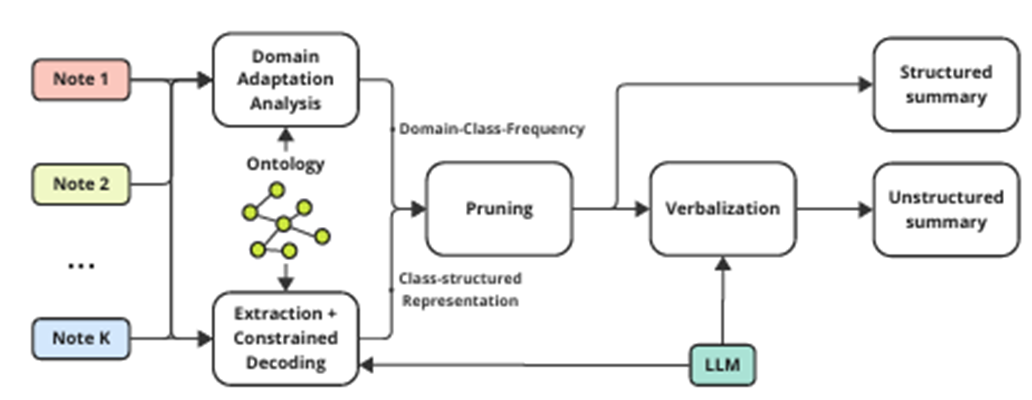 전체 프레임워크
전체 프레임워크
전체 파이프라인은 다음 4단계로 구성된다.
- 각 의학과에 맞는 DCF 사전 구축 (오프라인, 1회성 작업)
- 환자의 EHR을 온톨로지 기반 프롬프팅 + 제약 디코딩으로 CSR로 변환
- CSR을 목적에 맞는 DCF로 Pruning (도메인 적응)
- Pruning된 CSR을 그대로 사용(구조적 요약)하거나, LLM을 통해 Verbalize (비구조적 요약)
- Dataset: MIMIC-III (45,000건 이상의 중환자실 환자 입원 기록)
- Ontology: SNOMED-CT (포괄적인 의료 온톨로지)
- LLM: Phi-3 (3.5B), Zephyr-7b-beta
- Annotator: MedCAT (텍스트 ↔ SNOMED-CT 클래스 매핑)
2-1) DCF 구축 (Domain Adaptation Analysis)
DCF(Domain-Class-Frequency) 는 특정 의학과(도메인)와 관련이 높은 온톨로지 클래스들의 집합을, 각 클래스의 빈도수(관련도 점수)와 함께 정리한 Dictionary 형태의 데이터 구조이다.
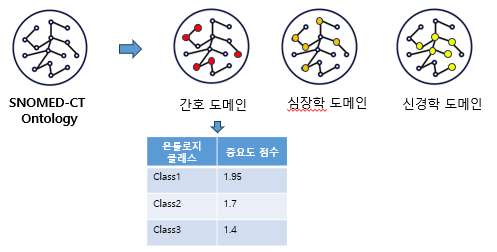 도메인과 클래스의 관계. 특정 도메인과 관련된 온톨로지끼리 모여있다는 보장이 없으며, connectivity는 온톨로지를 어떻게 설계하느냐에 따라 다름. 따라서 어떤 도메인에 어떤 클래스가 연관된 개념인지는 직접 텍스트를 통해 정리해야 함
도메인과 클래스의 관계. 특정 도메인과 관련된 온톨로지끼리 모여있다는 보장이 없으며, connectivity는 온톨로지를 어떻게 설계하느냐에 따라 다름. 따라서 어떤 도메인에 어떤 클래스가 연관된 개념인지는 직접 텍스트를 통해 정리해야 함
DCF 구축 과정은 다음과 같다:
- 특정 도메인 $D$에 속하는 임상 텍스트에 MedCAT annotator를 적용하여 SNOMED-CT 클래스를 태깅한다.
- 최소 등장 임계값 이상인 클래스들의 집합 $S$를 구성하고, 온톨로지를 따라 각 클래스의 조상 클래스(ancestors)도 $S$에 추가한다.
- $S$ 내 각 클래스의 빈도수를 계산하여 저장한다.
- 모든 도메인의 평균 DCF로 정규화(normalization) 한다. 이 단계를 통해 모든 도메인에서 공통적으로 등장하는 일반 의료 개념의 가중치를 낮추고, 도메인에 특화된 개념만 부각시킨다.
이렇게 구축된 DCF는 나중에 Pruning 단계에서 어떤 클래스 정보를 최종 요약에 포함시킬지 결정하는 기준으로 활용된다.
2-2) CSR 작성 (Information Extraction using Ontology-based Prompting)
CSR(Class-Structured Representation) 은 환자의 임상 노트 하나를, 해당 노트에서 감지된 온톨로지 클래스 → 관련 정보 요약(extracted value) 의 매핑으로 표현한 구조화된 데이터이다.
CSR 생성 과정:
- 임상 노트에 MedCAT annotator를 적용하여 언급된 SNOMED-CT 개념(클래스)을 추출한다.
- 각 개념에 대해 LLM에게 다음 프롬프트를 반복 적용한다:
“Here is a clinical note about a patient: [note]. In a short sentence, summarize everything related to the “[concept]” concept mentioned in the note. “[concept]” is characterized by [properties]. If nothing is mentioned, answer with ‘N/A’.”
- 온톨로지에서 해당 클래스의 restriction property(제한 속성) 를 프롬프트에 augmentation하여, LLM이 개념을 더 잘 이해하도록 돕는다 (RAG와 유사한 방식).
- 각 임상 노트마다 하나의 CSR이 생성되며, 이 과정은 노트별로 병렬 처리 가능하다.
2-3) 제약 디코딩 (Constrained Decoding)
CSR 작성(추출) 단계에서의 디코딩 전략이 이 논문의 핵심 기여이다. 단순히 프롬프트만 개선하는 것이 아니라, 빔 서치(Beam Search) 과정 자체를 온톨로지로 제약하여 더 사실에 가깝고 관련성 높은 답변을 유도한다.
각 빔의 점수 $BS$는 아래 세 가지 서브 점수의 합으로 계산된다:
\[BS = \text{LogSoftmax}(H + P + S)\]① Hierarchy Score $H$ (계층 점수)
\[H = H_{bf} \cdot \frac{1}{|C|} \sum_{c \in C} \mathbb{1}\{b \in A(c)\}\]- 생성된 빔 내 개념들이 기준 클래스 $b$의 하위 클래스(descendants) 에 해당하는지 측정한다.
- 예: “질병”을 요약하도록 요청했을 때, 빔에 “심근경색(Myocardial Infarction)”처럼 질병을 상속한 클래스가 포함되면 높은 점수를 받는다.
- $H_{bf}$: hierarchy boost factor (하이퍼파라미터)
② Property Score $P$ (속성 점수)
\[P = \frac{P_{bf} \sum_{c \in C} \mathbb{1}\{c \in P(b)\}}{|C||P(b)|} + R_2(T, P'(b))\]- 빔 내 개념이 기준 클래스의 restriction property 값과 연관되는지 측정한다.
- 예: “발열(Fever)”을 요약할 때 “체온(Body Temperature)”이 언급되면 높은 점수를 받는다.
- ROUGE-2 점수를 보조적으로 사용하여 annotator가 제대로 태깅하지 못한 경우도 커버한다.
- $P_{bf}$: property boost factor (하이퍼파라미터)
③ Similarity Score $S$ (유사도 점수)
\[S = S_{bf} \cdot R_2(b, N)\]- 생성된 빔이 원본 임상 노트 $N$과 얼마나 텍스트적으로 유사한지 ROUGE-2로 측정한다.
- 원본에 없는 내용이 생성되는 Hallucination을 억제하는 역할을 한다.
- $S_{bf}$: similarity boost factor (하이퍼파라미터)
이 세 점수의 합산으로, 온톨로지 구조에 부합하면서 원본 노트에 근거한 빔이 선택된다.
2-4) Pruning & Verbalization
Pruning: CSR이 생성된 후, DCF를 기준으로 도메인과 관련성이 낮은 클래스들을 제거한다. top-$k$ 빈도 클래스와, 온톨로지 계층상 $\alpha$ 노드 이내의 클래스들을 유지한다. 이 단계가 도메인 특화 요약의 핵심이다.
Verbalization: Pruning된 구조적 CSR을 동일한 LLM에게 한 번 더 forward pass하여 자연스러운 비구조적 텍스트 요약으로 변환한다. 의사가 읽기 편한 최종 요약문이 이 단계에서 생성된다.
3. Experiments & Results
실험 설정
| 항목 | 내용 |
|---|---|
| 데이터셋 | MIMIC-III (테스트셋 $\Omega$: 400 admissions, 3000+ 임상 노트) |
| 온톨로지 | SNOMED-CT |
| 모델 | Phi-3 (3.5B), Zephyr-7b-beta |
| Annotator | MedCAT |
| 비교 방법 | Greedy Search, Diverse Beam Search |
| 하이퍼파라미터 | $H_{bf}=3$, $P_{bf}=10$, $S_{bf}=10$, 빔 크기 10, $k=30$, $\alpha=2$ |
3-1) 도메인 적응 평가 (Domain Adaptation Score)
도메인 분류기(BERT fine-tuned on MIMIC categories)를 훈련하여 요약문이 목표 도메인에 얼마나 잘 맞는지 평가하였다.
| Method | Phi-3 | Zephyr |
|---|---|---|
| Greedy Search | 0.41 | 0.56 |
| Diverse Beam Search | 0.43 | 0.59 |
| Ours (Extraction+Pruning) | 0.86 | 0.78 |
Phi-3 기준으로 Greedy Search 대비 2배 이상의 도메인 적응 점수를 달성하였다. 프롬프트에 도메인을 명시하는 방식보다, 온톨로지 기반 Pruning이 훨씬 효과적임을 보여준다.
3-2) Hallucination 감소 평가
NLI 모델(DeBERTa, MNLI fine-tuned)을 사용하여 생성된 내용이 원본 임상 노트에 근거(Groundedness)하는지, 그리고 프롬프트 개념과 관련성이 있는지(Relevance)를 평가하였다.
| Phi-3 Gnd | Phi-3 Rel | Phi-3 Avg | Zephyr Gnd | Zephyr Rel | Zephyr Avg | |
|---|---|---|---|---|---|---|
| Greedy | 0.83 | 0.57 | 0.70 | 0.83 | 0.82 | 0.83 |
| Diverse Beam | 0.85 | 0.58 | 0.72 | 0.87 | 0.83 | 0.85 |
| Ours | 0.90 | 0.64 | 0.78 | 0.90 | 0.88 | 0.89 |
Greedy 대비 Groundedness +7%, Relevance +7%(Phi-3 기준)를 달성하였다. 제약 디코딩이 Hallucination을 실질적으로 줄임을 확인하였다.
3-3) 임상 요약 성능 (BHC Summarization)
MIMIC-III의 퇴원 요약(Brief Hospital Course, BHC) 생성 태스크에서 기존 방법과 ROUGE 및 Hallucination Score를 비교하였다.
| Fine-tuned | Method | R1↑ | R2↑ | RLSum↑ | HS(%)↓ | AHS(%)↓ |
|---|---|---|---|---|---|---|
| ✓ | SPEER | 25.90 | 7.10 | - | - | - |
| ✓ | Dual Transformer | - | 11.50 | 34.90 | - | - |
| ✗ | Baseline (Phi-3) | 26.59 | 4.75 | 13.85 | 45.70 | 38.68 |
| ✗ | Ours (Phi-3, E+P) | 28.41 | 5.47 | 13.93 | 37.95 | 33.08 |
| ✗ | Baseline (Zephyr) | 20.32 | 4.01 | 11.56 | 45.43 | 41.60 |
| ✗ | Ours (Zephyr, E+P) | 23.44 | 4.20 | 12.78 | 43.76 | 40.39 |
- Fine-tuning 없이도 Phi-3 기준 R1 28.41로 비파인튜닝 방법 중 최고 성능을 달성하였다.
- Hallucination Score(HS)를 Phi-3에서 45.70 → 37.95로 약 8%p 감소시켰다.
- Fine-tuned 모델보다 ROUGE 절대 수치는 낮지만, 도메인 특화 요약이라는 추가 기능을 제공한다는 점에서 비교의 의미가 있다.
4. 한계 및 의의
한계
- 계산 비용: 온톨로지 클래스 수만큼 inference pass를 반복하므로 scalability 문제가 있다. 병렬화로 일부 해소 가능하다.
- 하이퍼파라미터 민감도: 프롬프트 형식, $k$, $\alpha$, boost factor 등 튜닝이 필요한 변수가 많다.
- Annotator 의존성: MedCAT처럼 고품질 annotator가 존재하는 온톨로지에서만 바로 적용 가능하다.
- 인간 평가 부재: 자동 메트릭만으로 평가하였고, 실제 의료 전문가에 의한 정성 평가가 이루어지지 않았다.
의의
- 온톨로지를 RAG 방식의 Input Augmentation이 아닌, Generation 단계의 Constraint로 활용한 최초 시도 중 하나이다.
- 도메인 적응(Pruning)과 사실성(Constrained Decoding)을 분리된 모듈로 다루어, 파이프라인의 해석 가능성(interpretability)을 높였다.
- 어떤 LLM에도 token probability만 접근 가능하면 적용 가능한 일반적인 프레임워크이다.
5. 참고 문헌
- Mehenni, G., & Zouaq, A. (2024). Ontology-Constrained Generation of Domain-Specific Clinical Summaries. EKAW 2024. arXiv:2411.15666.
- Lewis, P., et al. (2020). Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks. NeurIPS 2020.
- Johnson, A.E., et al. (2016). MIMIC-III, a freely accessible critical care database. Scientific Data.