LLM Knowledge와 Real-World의 misalignment
LLM에 대한 기본적인 Review와 임베딩 misalignment

이 포스팅은 25년도 광주과학기술원(GIST) 석사과정을 진행하는 제 연구 주제와 관련된 정리글입니다.
LLM의 작동 원리와 학습 방식
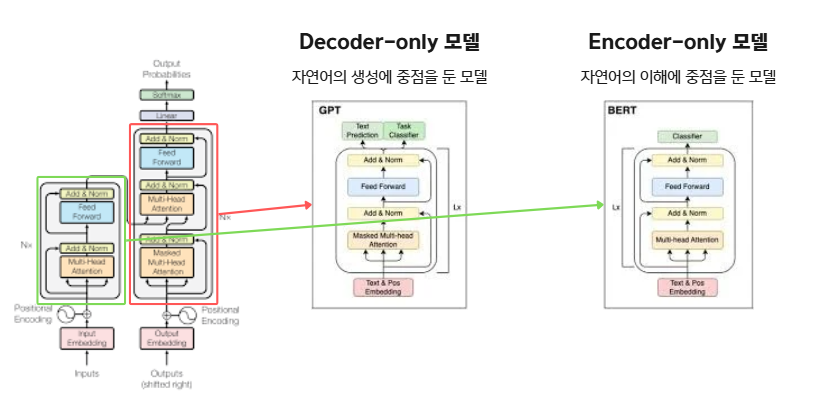
Transformer 아키텍처의 등장 이후 이를 기반으로 한 언어 모델들이 많이 탄생하고 있다. 이 언어 모델들은 크게 2가지로 분류할 수 있다.
 트랜스포머와 LLM의 탄생
트랜스포머와 LLM의 탄생
- Encoder-only Model:
- Transformer의 인코더만을 가져와, 문장 이해에 더 큰 성능을 가지지만 텍스트 생성을 할 수는 없다.
- 최종 생성된 latent vector를 기반으로 한 downstream task에 강력하다.
- BERT계열 모델들이 이에 해당된다.
- Decoder-only Model: Transformer의 디코더만을 가져와, 텍스트를 생성하는데에 강점을 지닌다.
- 최종 생성된 latent vector가 vocab lookup을 통해 바로 텍스트로 변환된다.
- GPT 계열 모델들이 이에 해당된다.
두 유형의 언어 모델 모두 동일한 학습 철학을 토대로 만들어졌다. 바로 표현학습의 기법 중 하나인 자기지도 학습 기법을 사용한, Token Prediction Task다.
Pre-training - Token Prediction
 Next Token Prediction
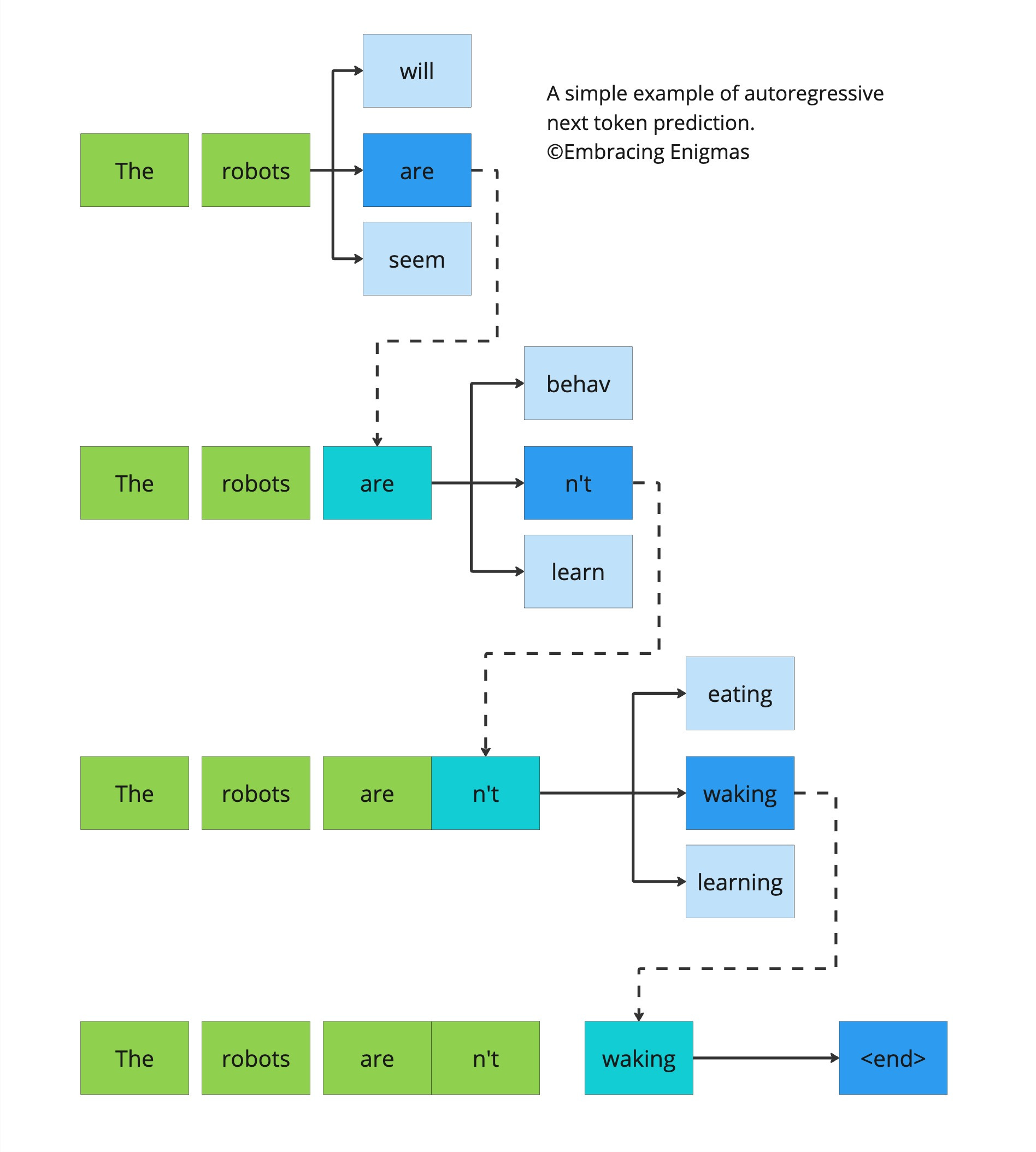
Next Token Prediction
Pre-training은 LLM이 지식을 쌓는 과정이라고 생각하면 된다. LLM은 가려진 토큰을 예측하는 Task를 수행하며, 내부에 존재하는 모든 tunable parameter들은 이 token prediction을 잘하는 방향으로 학습된다.
이 과정에서 언어 모델은 입력 텍스트를 최대한 잘 따라하는 통계적 앵무새로서 학습하게 된다.
next token preditcion: 단방향으로 attention을 계산하는 Decoder의 특성을 활용하여, autoregressive하게 학습을 진행한다. 모델은 현재까지의 입력을 토대로 직후의 토큰을 예측한다.
masked token prediction: 양방향으로 attention을 계산하는 Encoder는 전체 문맥을 사용하기 때문에 이전 토큰끼리만의 정보를 사용할 수 없으며, 따라서 next token prediction을 할 수 없다. 때문에 문장 전체 중 일부 토큰을 마스킹한 뒤 가려진 토큰을 예측한다.
현대의 LLM은 이외에도 다양한 pre-training task를 수행하지만, 모두 표현학습의 철학을 따르고 있다. LLM은 이 단계에서 데이터의 ‘표현’을 학습하게 된다.
Fine-tuning - Knowledge Alignment
이 단계는 지식을 쌓은 LLM이 해당 지식을 우리에게 올바른 형태로 표현 가능하도록 하는 단계라고 할 수 있다.
Fine-tuning에 사용되는 Task로는 텍스트 분류, QA, 요약 등이 있으며, 이 과정에서 강화학습이 사용되기도 한다.
 GPT의 인간 피드백 기반 강화학습을 이용한 Fine-tuning(RLHF)
GPT의 인간 피드백 기반 강화학습을 이용한 Fine-tuning(RLHF)
우리가 chatGPT를 사용할 때 가끔 보이는 두 답변 중 선호 답변 고르기도 이같은 fine-tuning의 한 과정이다. 인간의 피드백을 통해 모델을 개선하는 RLHF(Reinforcement Learning with Human Feedback) 기법이다.
Token Prediction만으로 이 정도의 수준을?
현재 존재하는 LLM들은 모두 이런 방식으로 학습된다. 대규모 데이터로 거대한 지식을 보유하는 통계적 앵무새를 만들어낸 뒤, 다양한 Fine-tuning 기법을 통해 그 지식을 잘 표현할 수 있도록 만든다.
여기까지만 보면 LLM이 작동하는 것이 기적인 것처럼 보이기도 한다. 앵무새처럼 따라만 하는 것이 지식을 쌓는 것이라고 할 수 있을까? Fine-tuning으로 모델의 출력을 바꾸는 것이, 내제된 지식을 표현하는 법을 가르쳐 주는 것이 맞을까?
LLM은 이처럼 일반적인 인공신경망보다 그 black-box성이 짙은 모델로 간주된다. 때문에 LLM의 한계를 지적하고, 과대평가되었다고 주장하는 사람들도 많다.
이같은 의견에 Ilya Sutskever는 인터뷰 영상에서 이같이 답한다.
Misalignment 문제
하지만 아무리 Fine-tuning을 진행했다고 하더라도, Data-Driven인 이상 LLM의 내제된 지식을 실제 세계와 100% 매칭시키는 것은 한계가 있다. 그 예시가 바로 다음과 같은 경우다.
Hallucination
 할루시네이션의 가장 대표적인 예시 - 세종대왕 맥북 던짐 사건
할루시네이션의 가장 대표적인 예시 - 세종대왕 맥북 던짐 사건
위 사진은 할루시네이션을 가장 잘 설명해주는 예시다. Hallucination은 생성형 Task를 수행하는 Decoder-only 모델들에서 발생하는 전형적인 문제다.
모델은 실제 세상에 존재하지 않는 정보를 ‘그럴듯하게’ 만들어낼 수 있는데, 이는 훈련 데이터에 없거나 불완전하게 반영된 정보를 보완하려다 생기는 현상이다. GPT 시리즈와 같은 모델들이 가끔 잘못된 인용이나 역사 왜곡을 일으키는 것도 이와 같은 이유다.
Embedding Misalignment
그렇다면 생성 Task가 아닌 데이터 임베딩을 진행하는 Encoder-only 모델은 괜찮을까? 아쉽게도 그렇지 않다.
Encoder 기반 LLM은 입력된 문장을 고차원 벡터로 압축하는 ‘의미 표현’을 주된 목표로 삼는다. 하지만 이러한 임베딩 또한 학습 데이터에 기반한 통계적 표현에 불과하기 때문에, 실제 세계의 의미론적 관계와 불일치할 수 있다.
예를 들어, “원전”과 “탄소중립”이 자주 함께 등장했다고 해서 이 둘이 항상 긍정적으로 연결된 것은 아니다. 환경단체의 비판적 담론 안에서도 같이 등장할 수 있기 때문이다. 하지만 임베딩은 이 두 개념 사이의 거리를 가깝게 만들 수 있고, 이로 인해 downstream task에서 잘못된 해석을 유도할 수 있다.
이는 representation level에서의 misalignment로, downstream에서 어떤 논리적 판단이나 분류를 하더라도 본질적으로는 잘못된 의미 공간 위에서 판단이 이뤄질 수 있음을 시사한다.
에너지 도메인에서 발생 가능한 misalignment 문제
특히 에너지와 같은 실세계 시스템에 LLM을 적용할 경우, misalignment의 영향은 더욱 치명적이다. 예를 들어, 스마트 그리드 운영에서 “이상 상태”를 감지하기 위한 텍스트 기반 분석에 LLM을 활용한다고 할 때, 모델이 실제 물리적 계측 정보에 기반하지 않고 텍스트 패턴만 학습했다면, 중요한 이상 상황을 무시하거나 반대로 정상 상황을 이상으로 오인할 수 있다.
또 다른 예시는 에너지 설비의 고장 보고서 자동 요약이다. LLM이 도메인 지식 없이 일반적인 표현을 사용하면, 원인이나 조치 사항을 왜곡하거나 핵심 정보를 빠뜨릴 수 있다. 이는 운영자의 잘못된 판단으로 이어지고, 실제 비용 손실로 직결될 수 있다.
이처럼 LLM의 misalignment는 단순한 출력 오류가 아닌, 실제 의사결정에 영향을 미치는 치명적 오류로 작용할 수 있다.
해결책
위같은 예시들을 재현해보려고 하면, 정상적인 답변을 뱉는 경우가 많다. 이는 chatGPT에서 사용되는 모델이 지속적인 RLHF와 Fine-tuning을 통해 빠르게 대처하기 때문이다.
하지만 만약 모델을 의사결정 자동화에 사용하고자 한다면 어떨까? LLM을 의사결정 자동화에 사용하는 경우 문제가 발생한다. 의사결정 과정에서 misalignment 문제가 발생하고나면, 뒤늦게 오류 수정을 위한 Fine-tuning을 해봤자 잘못된 결정으로 인한 피해는 벌어진 뒤니까.
때문에 LLM은 아직 인간을 완전히 대체하지 못한다. 모든 AI가 다 그렇긴 하지만, LLM은 특히 그렇다. 이는 1) 설명가능성(Explainability)이 떨어지며, 2) LLM이 수행하는 작업이 복잡하여 문제가 생겼을 때 즉각 human-control로 전환하기 어렵기 때문이다.
그러므로 설명가능성을 향상시키고, 언제든지 사람이 수행하도록 전환 가능한 의사결정 모델을 만들기 위해선 LLM이 생각하는 방식을 어느 정도 제한해야 할 필요가 있다. 이를 Grounding이라고 부른다.
아래는 LLM의 Grounding에 대한 예시다.
RAG
RAG란 Retrieval Augmented Generation의 약자다.
RAG는 LLM이 외부 지식에 접근할 수 있도록 하는 방법론이다. 생성 전, 관련 정보를 검색 시스템을 통해 불러오고, 그 내용을 바탕으로 텍스트 생성을 수행한다.
즉, 모델 내부 파라미터에 저장된 지식이 아닌, 항상 최신화되고 정확한 외부 지식을 참조함으로써 Hallucination을 줄일 수 있다. LLM의 유창성과 Retrieval System의 정확성을 결합한 접근법이라 볼 수 있다.
다만, 검색 결과의 품질에 따라 성능이 좌우되며, 문맥에 부적절한 검색결과가 포함되면 오히려 혼란을 줄 수 있다. 또한 Retrieval 과정이 별도 시스템으로 분리되므로, Latency와 System Complexity도 고려해야 한다.
Ontology기반 KG(Knowledge Graph)
Ontology는 도메인 지식을 계층적으로 정리한 개념 구조이며, KG는 이러한 개념들을 노드-엣지 구조로 나타낸 그래프다.
LLM을 KG와 결합할 경우, 모델이 도메인 내 개념들의 관계를 일관성 있게 인식할 수 있도록 유도할 수 있다. 예를 들어, ‘발전기 → 발전기 고장 → 정전 가능성’과 같은 연쇄 구조를 통해 모델이 단순 통계적 연관이 아닌, 논리적 추론 기반의 응답을 할 수 있게 된다.
특히 에너지 도메인처럼 구조화된 지식이 중요한 분야에서는 KG와 LLM의 결합이 매우 유효한 방식으로 평가받고 있다.
Follow-up Article
LLM Knowledge Gap을 해결하기 위한 방법으로 다음 3가지 논문을 리뷰해보고자 한다.
RAG: https://arxiv.org/abs/2005.11401?ref=pangyoalto.com RAG는 생성형 모델의 디코더와 결합하여 텍스트 생성의 신뢰도를 높이는 기법으로 알려져 있다. 하지만 retriever의 성능에 따라 전체 시스템의 정확도가 좌우된다는 점에서, retriever의 fine-tuning이나 domain-specific indexing 전략이 중요하다.
K-BERT Knowledge Graph를 삽입하여 BERT의 embedding space를 조정하는 방식이다. KG 삽입을 위해 soft-position과 soft-segmentation encoding을 도입해 구조적 지식과 문맥 정보를 동시에 반영한다.
LLMs4OL 최근 연구에서는 LLM을 직접 KG 생성이나 Ontology 추출에 사용하는 시도도 이어지고 있으며, 이는 기존의 LLM fine-tuning 방식에서 벗어나 Knowledge Injection 관점의 접근이다.